Leveraging Ghidra to establish context and intent behind suspicious strings. Taking things one step further after initial analysis tooling like Pe-Studio and Detect-it-easy.
This is a great technique for working with Ghidra and establishing a starting point for analysis. It reduces total investigation time and allows one to determine why and how a string is contained within a file.
A string cross-reference is a means for seeing where a string is used within a binary.
This can be used to establish context around a string and determine whether it is malicious, benign or at least something to keep track of.
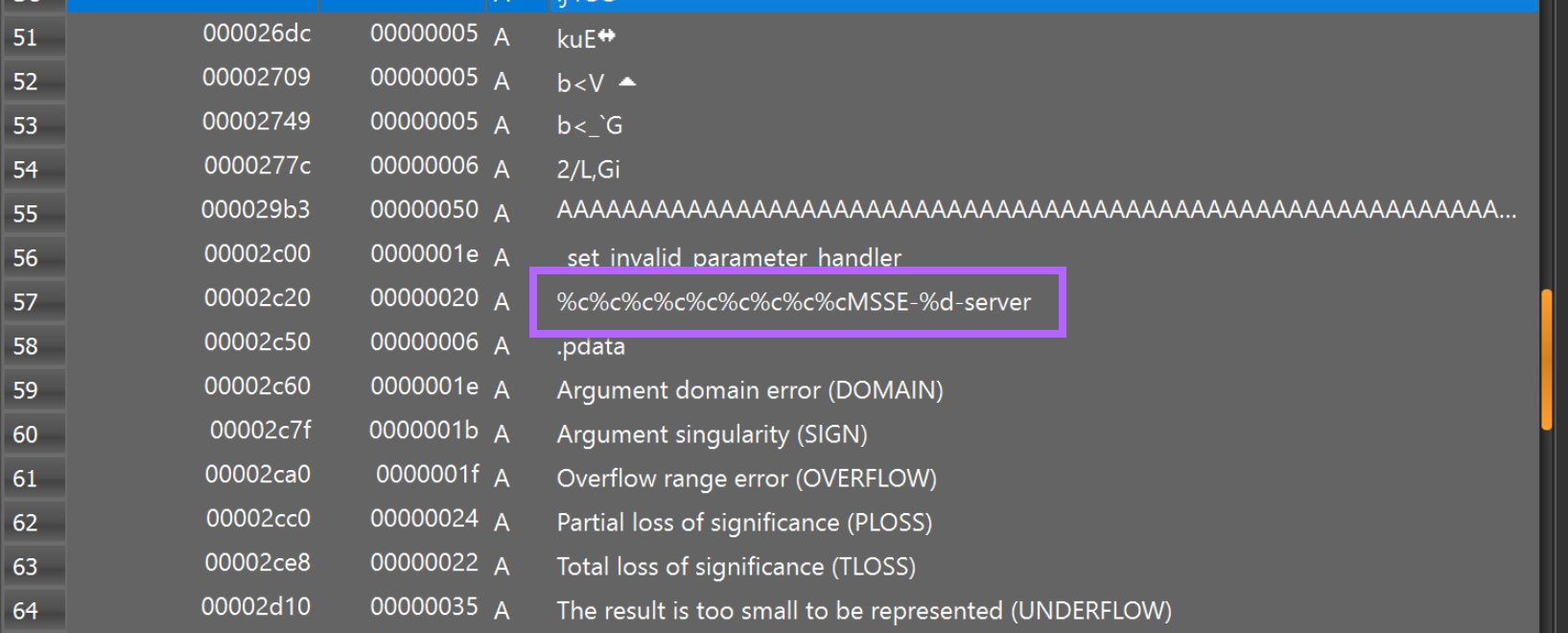
In this sample, there is a strange string that may be worth investigating. This string can be seen in detect-it-easy, pestudio, or any other tool that performs a string search.
We can establish more context on this string with Ghidra and the Search -> For Strings function.
From here, we can set Ghidra to search all loaded content for strings.
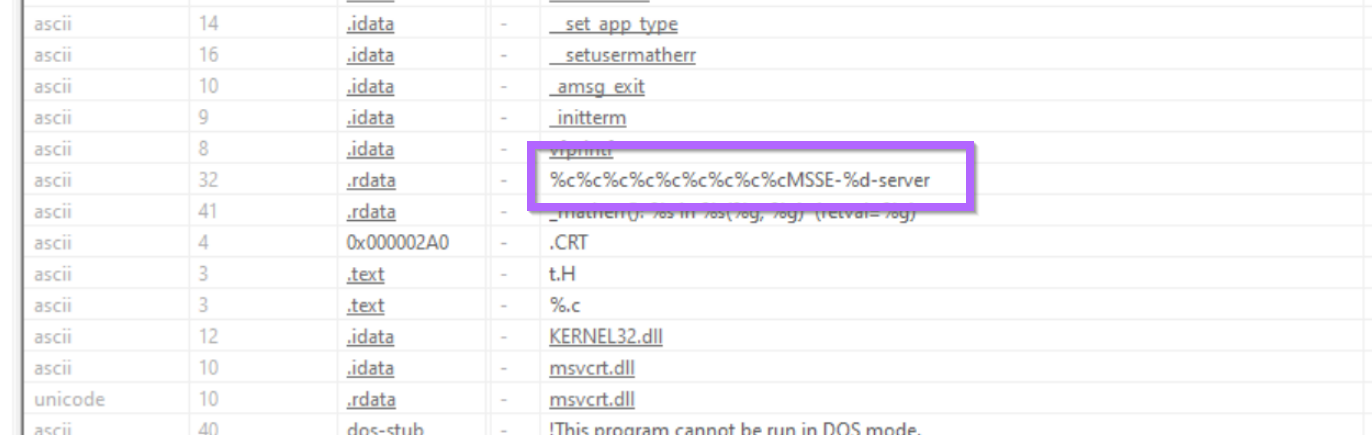
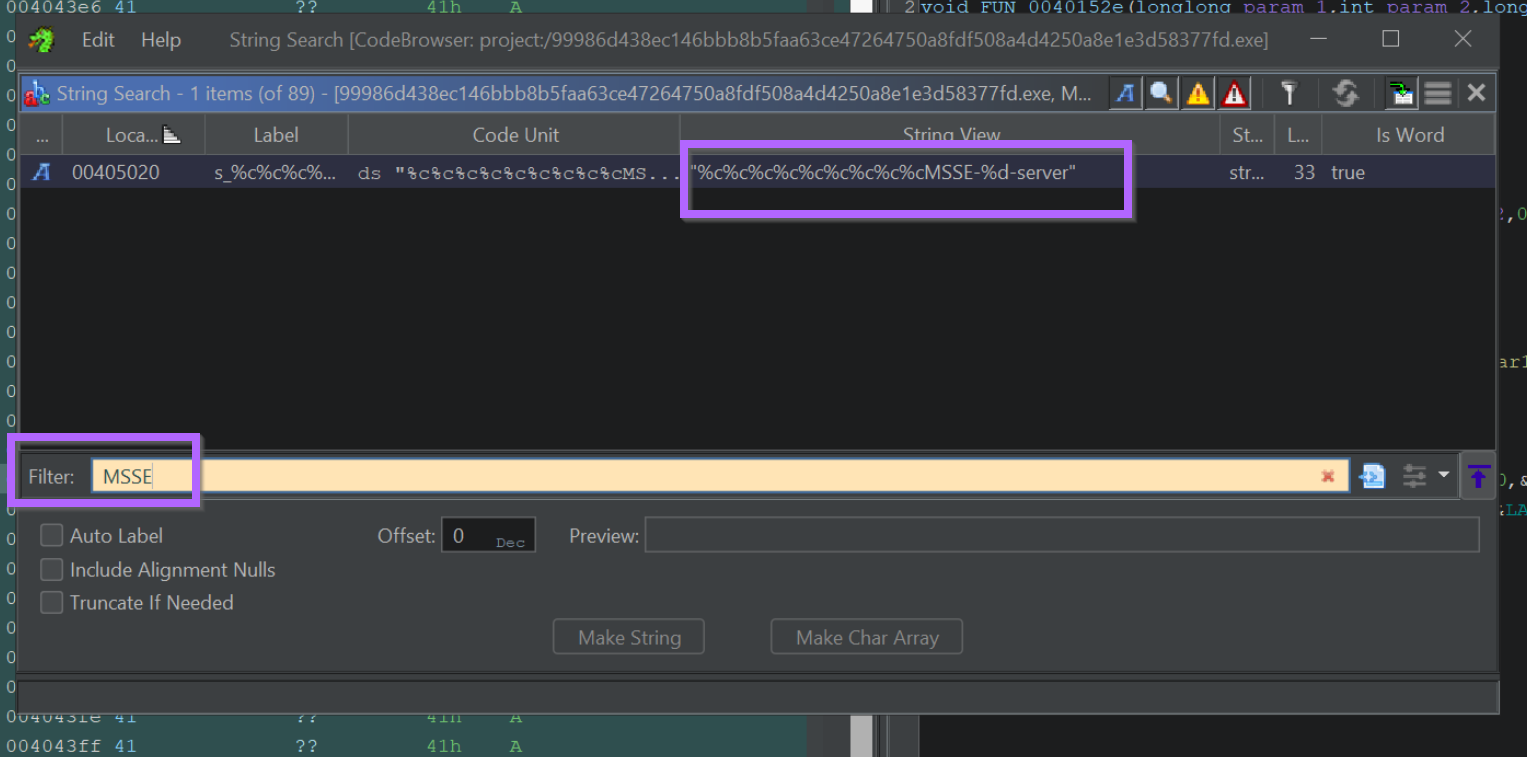
From here we can search all available data for the string %c%c%c%c%cMSSE-%d-server
To make things easier, we can filter on the partial string MSSE
We now have a match on the same string found within detect-it-easy.
By double-clicking on the returned string, we can view it in memory and note that it has one cross reference (XREF).
The presence of only a single XREF means that the string is only accessed once within the code.
By clicking on the function name in the above cross reference, we can see where the string is used within the file.
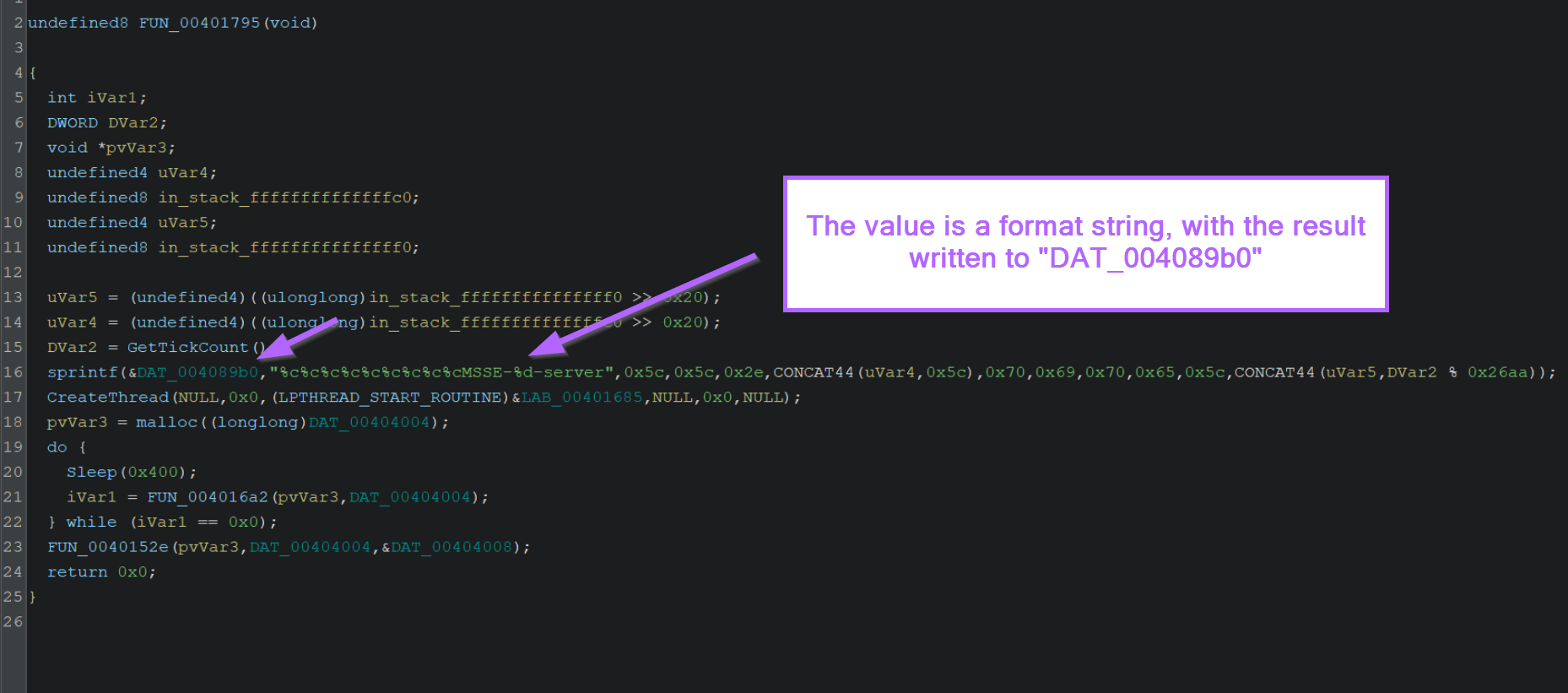
Although it's slightly difficult to read, the string is a format string populated with random values (replacing the %c).
After the random values are added, the resulting string is written to DAT_004089b0
Knowing where the string is being "written" to DAT_004089b0, we can perform a cross reference on the newly written value.
This will inform us where exactly the resulting string is used.
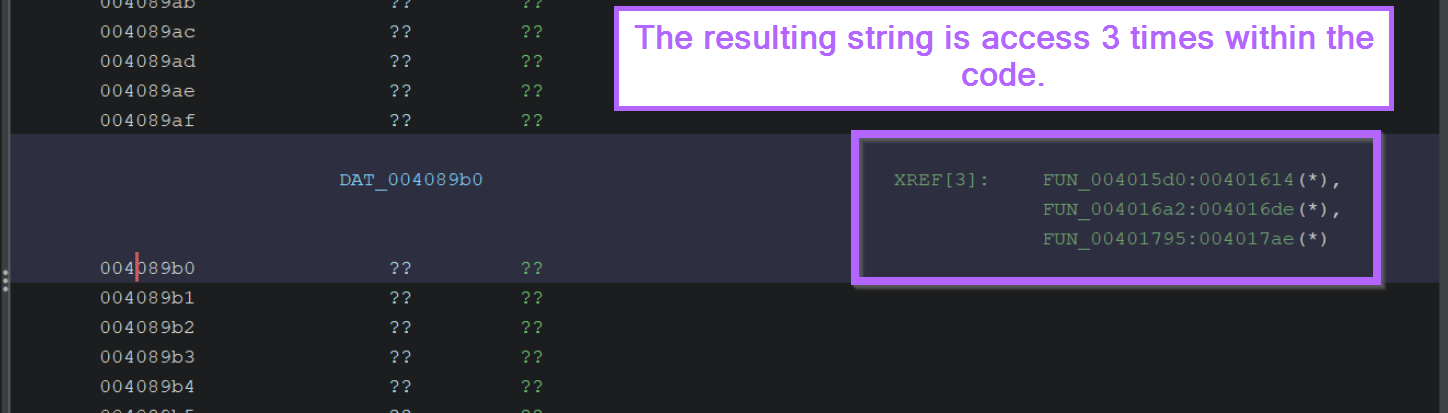
By double-clicking on DAT_004089b0 in the decompiler window, it will show us the location and any associated references. (In this case there are 3)
If we click on the first function FUN_004015d0, we will be taken to a new location in the decompiler window.
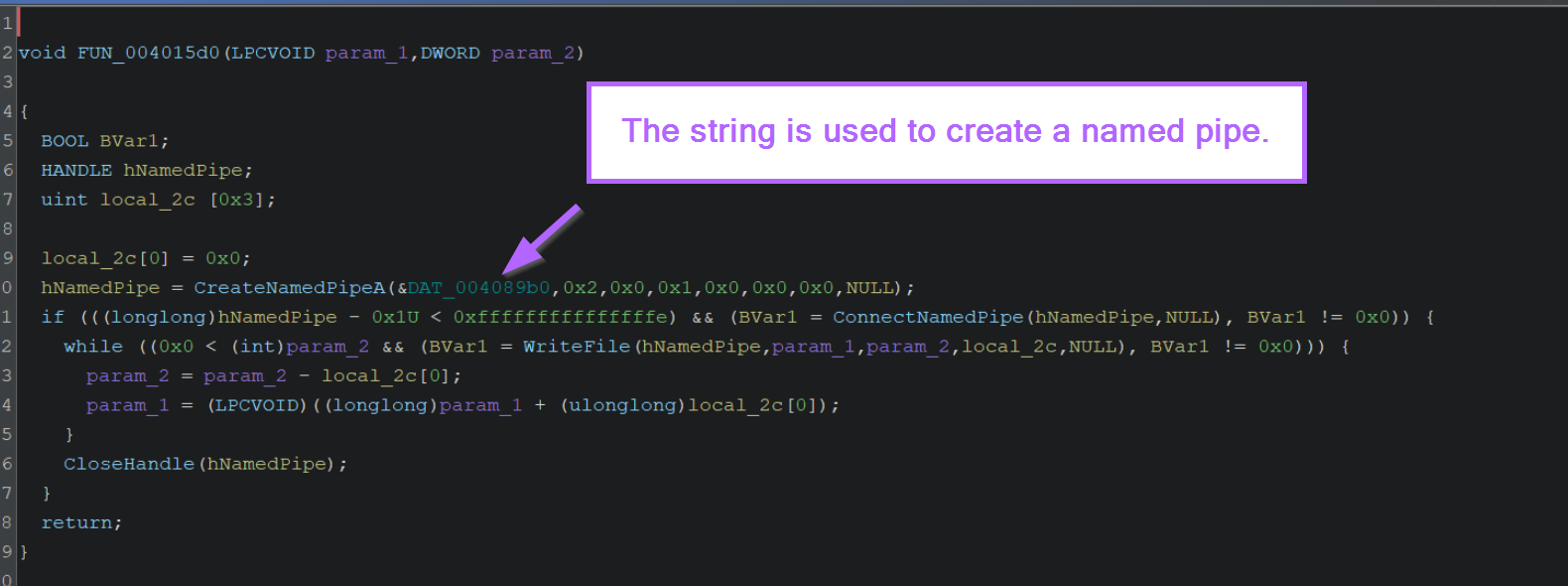
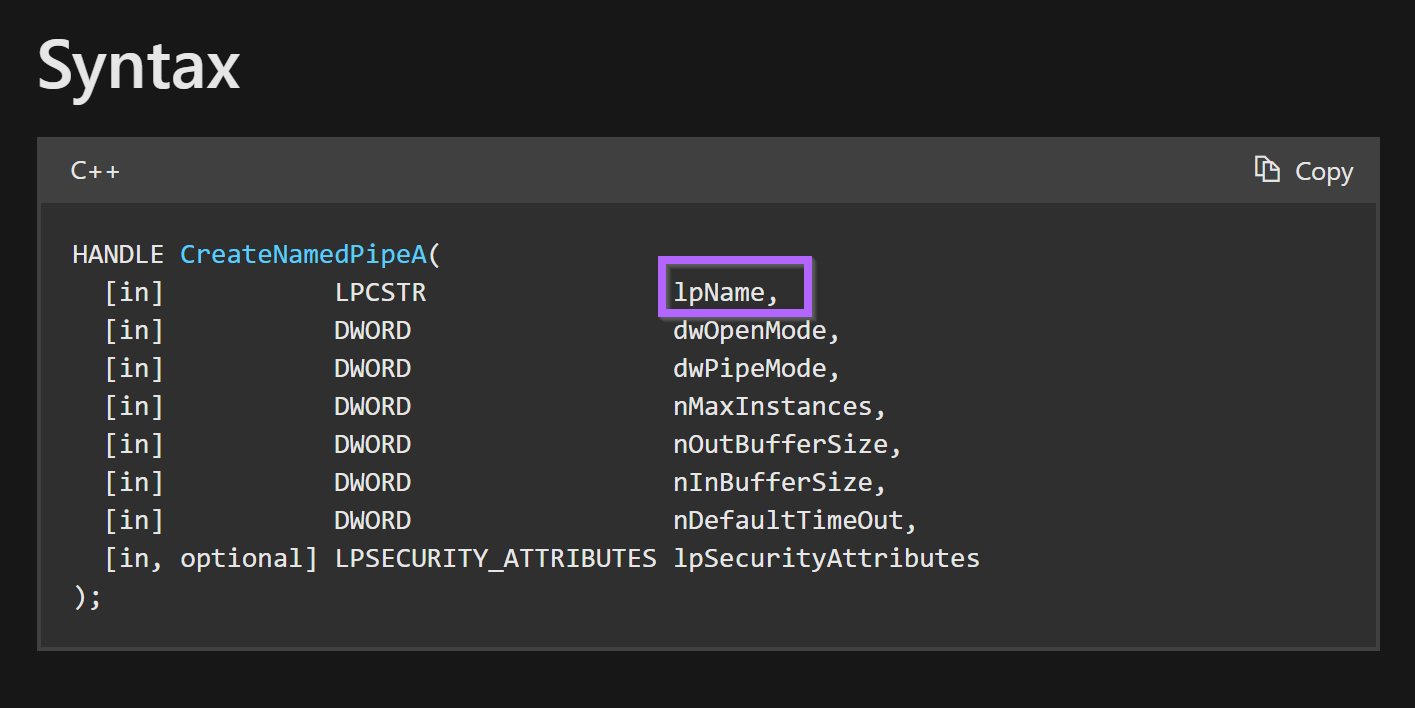
Within this function, we can see that the DAT_004089b0 (which contains the resulting value from our initial string), is used as the name of a named pipe via CreateNamedPipeA.
We know that the value is used as the pipe name as it's contained in the first argument passed to CreateNamedPipeA.
At this point, we have verified the context of the string and determined that it's a format string. The format string is ultimately used to create a named pipe via CreateNamedPipeA.
Pipes are somewhat confusing, but in this context, they're used to transfer the shellcode contained within the file. This is something we will cover in a later piece. (There are some great blogs already on the topics here and here)
Although this may not seem interesting, named pipes are strong indicators that can be hunted with EDR and DFIR tooling. On occasions, hardcoded pipe names can also be used to create Yara rules.
Using Strings to Identify New Samples
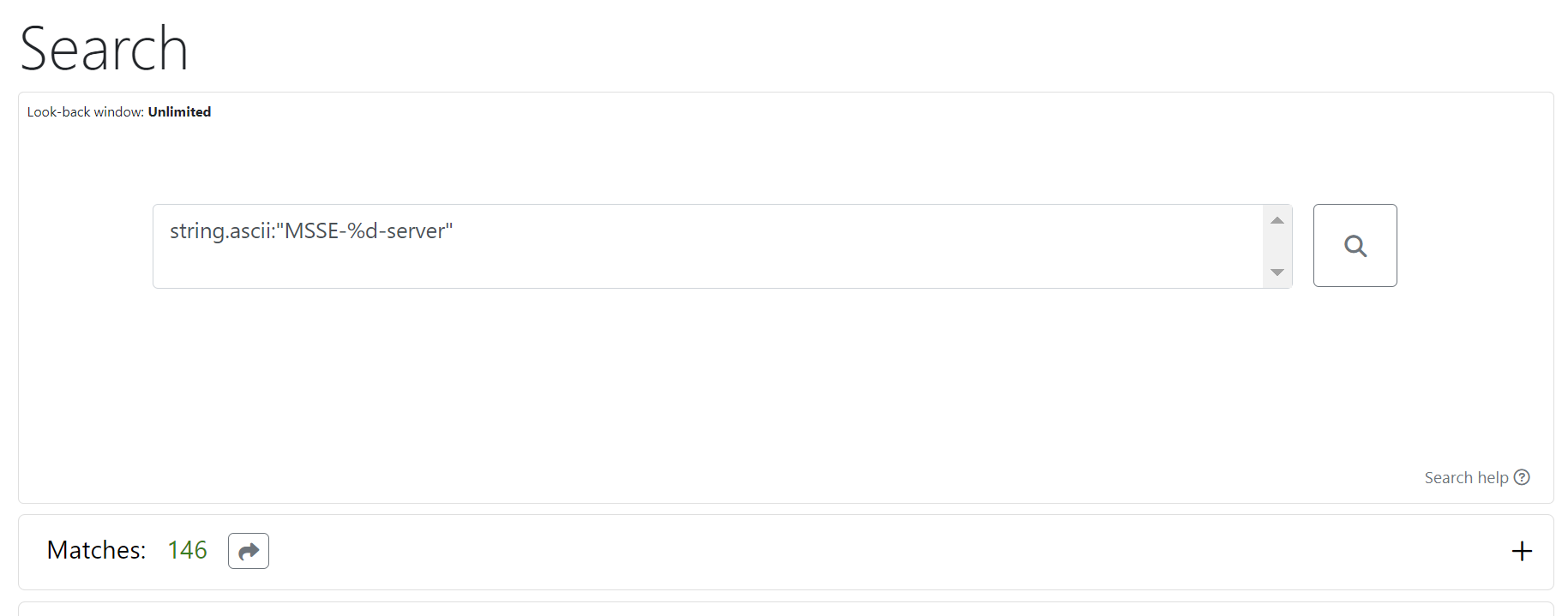
For example, if we search for string.ascii:"MSSE-%d-server" on Unpacme, we can identify another 145 related samples.
Obtaining Encrypted Content Using a Debugger
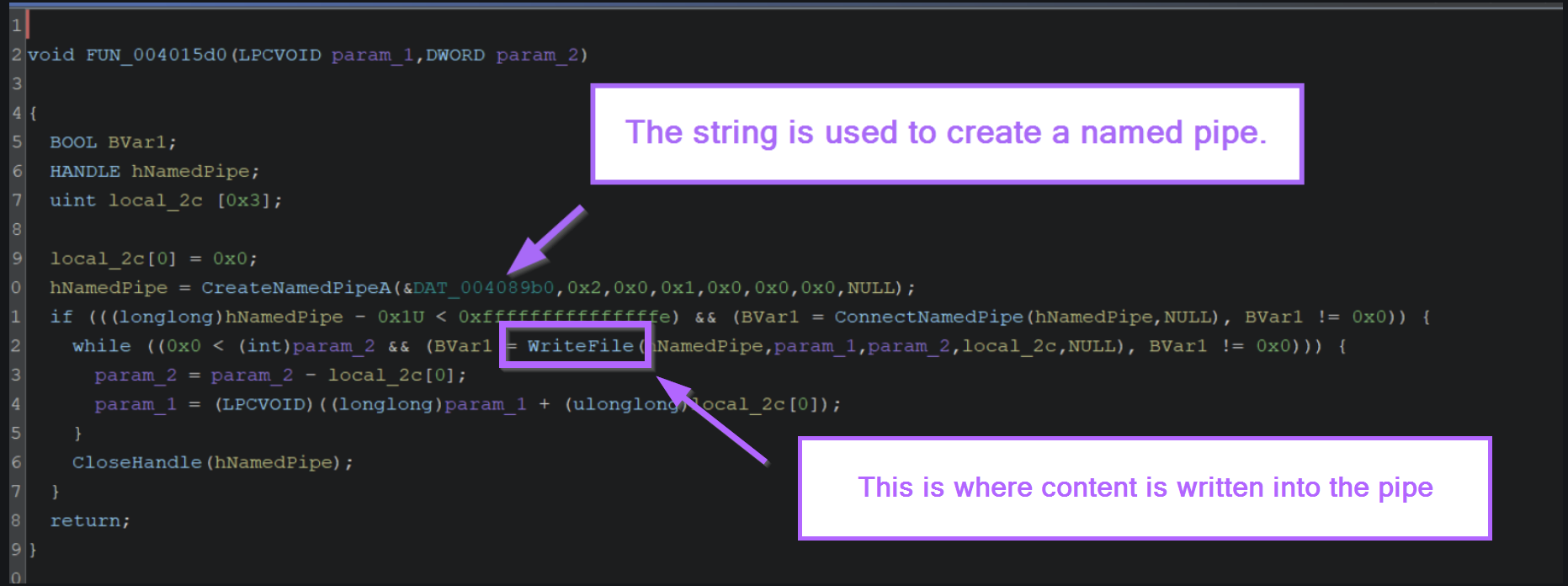
If we jump back a few screenshots, we can see where the named pipe is created with CreateNamedPipeA.
If we look at the two lines below CreateNamedPipeA, we can also see a reference to ConnectNamedPipe and WriteFile. This is where encrypted content is written into the named pipe.
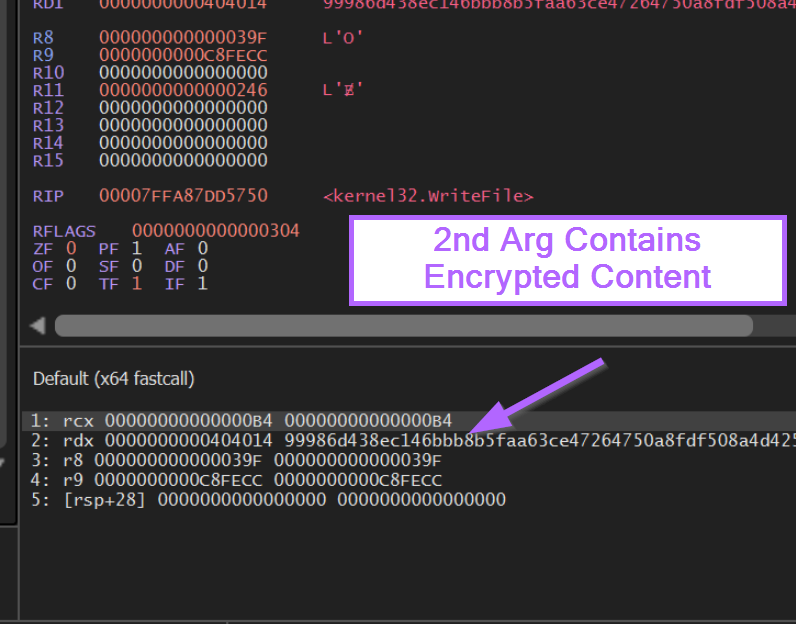
We can use this knowledge to set a breakpoint on WriteFile and obtain the content.
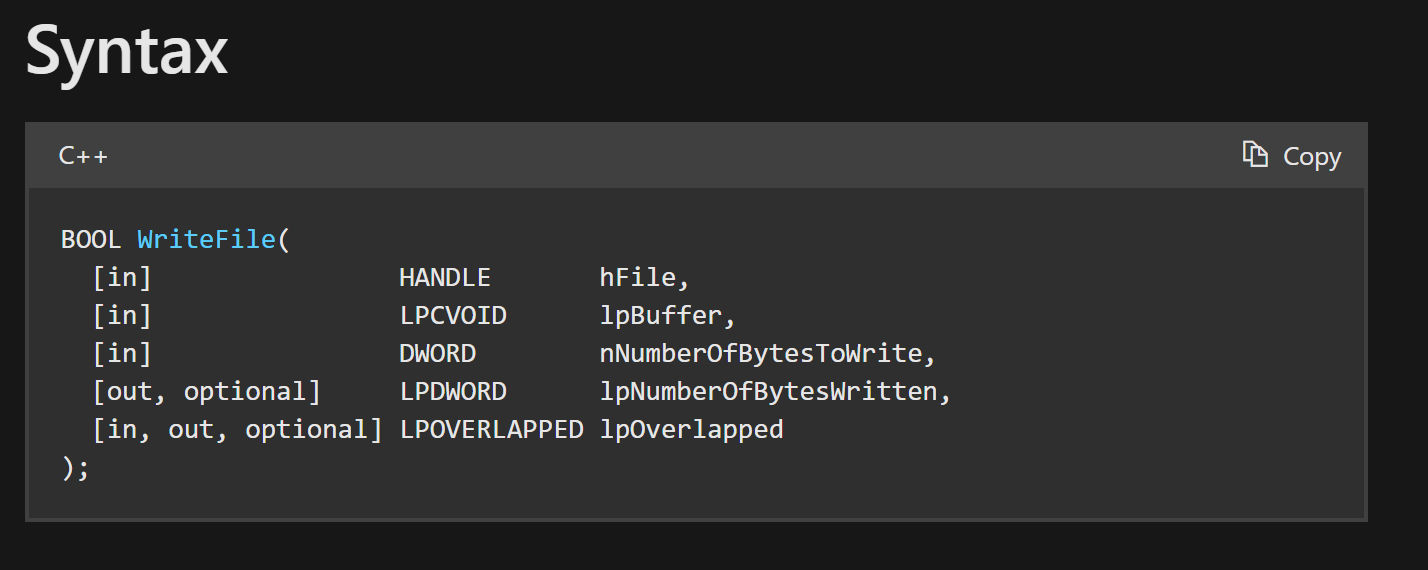
After setting a breakpoint on WriteFile with bp WriteFile, we can observe the arguments in the screenshots below. (We can google WriteFile to view the Microsoft documentation stating that the buffer is contained in the second argument.
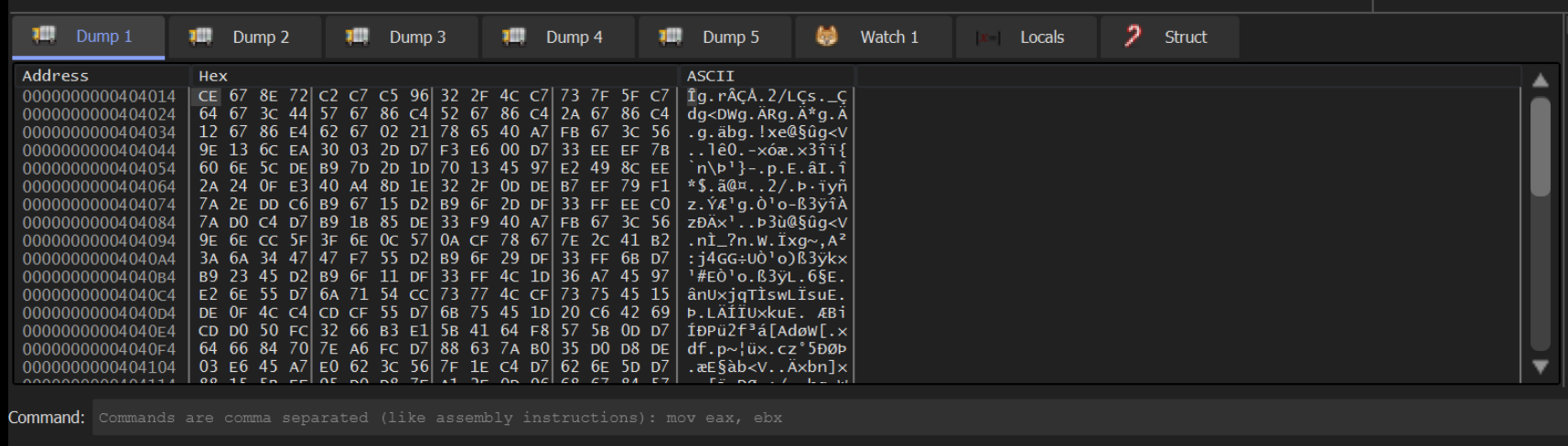
If we take the 2nd argument and Follow in Dump, we can obtain the encrypted malware content.
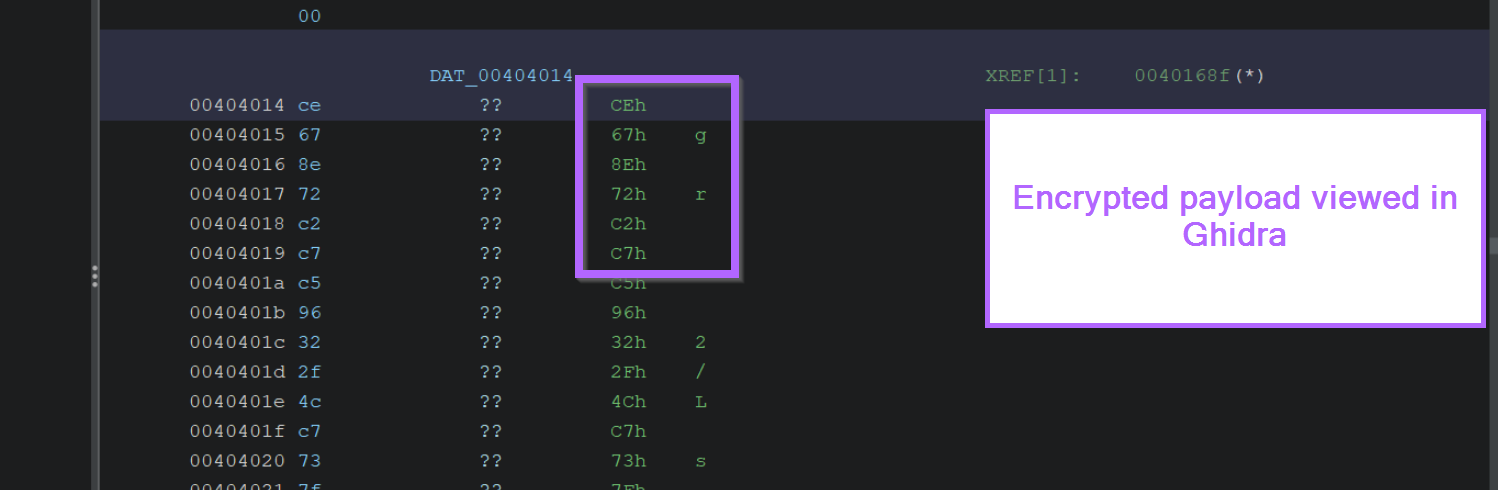
Comparing this to the same encrypted content in Ghidra, we can see that the bytes line up. CE 67 8E 72 etc
Sign up for Embee Research
Malware Analysis and Threat Intelligence Research
No spam. Unsubscribe anytime.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.